学院新闻
college news

论文简介
论文题目:phd: a chatgpt-prompted visual hallucination evaluation dataset
论文作者:jiazhen liu, yuhan fu, ruobing xie, runquan xie, xingwu sun, fengzong lian, zhanhui kang, xirong li
录用会议:cvpr 2025(入选highlight)
论文简要情况:
近期,国际计算机视觉与模式识别会议 (cvpr) 2025发布录用论文的报告形式。李锡荣教授团队关于多模态大模型幻觉评测的论文入选highlight。cvpr 2025共收到有效投稿13008篇,最终录用2878篇,录用率22.1%。其中387篇论文被选为highlight,仅占录用论文的13%。cvpr与iccv、eccv并称为计算机视觉领域三大顶会。其严苛的评审体系和高影响力意味着被接收论文代表了当前计算机视觉研究的最前沿成果。
该论文针对多模态大模型(mllm)在视觉问答中因视觉模糊、多模态输入冲突和常识冲突等三大成因而产生的“幻觉”问题,提出了phd评测基准。该基准包含phd‑base、phd‑sec、phd‑icc和phd‑ccs四种模式,覆盖对象、属性、情感、位置和计数五类视觉识别任务,共20种评测场景。论文依托基于chatgpt与clip的半自动化数据生成流水线,在14648张日常图像与750张反常识(ccs)图像上生成了10万多个vqa三元组样本。所有数据均显式标注了容易引发幻觉的因素(hitem)以及对应的幻觉成因,因此能够有效剖析多模态大模型的幻觉倾向,从而为视觉-语言对齐与mllm幻觉抑制研究提供了全新工具与分析视角。
论文概述
近年来,mllm虽取得了显著进展,但其在视觉问答中频繁出现的“幻觉”问题也日益凸显。为客观评测这种现象,研究者们陆续构建了多种幻觉数据集,其核心在于引入易诱发模型产生错误的“幻觉项”(hallucinatory item, hitem)。然而,现有幻觉评测数据集在hitem的挑选过程中并未与幻觉成因建立显式关联,导致评测易出现性能饱和。针对这一短板,本论文从幻觉的三大根源出发,即视觉模糊、多模态输入冲突、以及反常识冲突,针对性地设计评测模式并选取相应的hitem,构建起直接对应这三种幻觉来源的phd基准数据集,参见图1。
1.视觉模糊:图像细节不足,导致模型难以做出精准判断;
2.多模态输入冲突:提示文本与图像信息不一致时,模型往往偏向文本而忽略视觉证据;
3.反常识(counter-common-sense, ccs)冲突:当图像内容与模型内在常识相矛盾时,模型倾向于诉诸“世界知识”而非视觉输入。

图1. 多模态大模型的三大幻觉来源,包括(a)视觉模糊、(b)模态输出冲突、(c)反常识冲突。phd基准数据集直接与这三大幻觉来源相关。
四种评测模式 × 五类视觉任务
基于上述三种幻觉来源,phd基准数据集针对性地设计了四种评测模式和五类视觉识别任务构成,共计20种场景组合,能够全面覆盖并区分不同幻觉成因:
phd‑base:基础问答模式,直接针对日常图像提出二元yes/no问题,用以衡量模型在无任何干扰下的视觉理解能力,对应幻觉来源i;
phd‑sec:似是而非上下文模式,在问题前加入与图像“似是而非”的文本描述,模拟新闻报道或产品说明中常见的“相似但不完全匹配”场景,对应幻觉来源ii;
phd‑icc:错误上下文模式,在问题前添加与图像明确矛盾的文本,测试模型在多模态输入冲突时的抗干扰能力,对应幻觉来源ii;
phd‑ccs:反常识图像模式,采用ai生成的“违反常识”图像(如“在水下生长的树”),通过yes/no问题检测模型对内在常识与视觉事实冲突的处理方式,对应幻觉来源iii。
五类任务则涵盖对象识别、属性识别、情感理解、位置判断与计数,既包括低级视觉要素,也涉及中级推理层面,各模式与任务交叉形成20个细粒度评测场景,帮助研究者从整体与局部两方面深入剖析模型幻觉行为。图2详细展示了不同模式与任务的数据。

图2. phd基准数据集展示,包括phd-base, phd-sec, phd-icc和phd-ccs。涵盖容易诱发模型产生幻觉的hitem、模态冲突上下文和反常识图像。
chatgpt辅助的半自动化数据构建流水线
phd数据集紧密对应幻觉的三大来源,通过在现有tdiuc数据集基础上,借助clip、gpt‑4o mini及aigc工具,实现大规模、批量化的数据生成与改造,如图3所示,步骤包括:
1.任务特定的hitem选择
针对每一视觉任务,先从手工扩展的关键词词表(如颜色、对象、属性等)中剔除真实标签,生成候选干扰项;
利用clip计算每个候选项与图像的余弦相似度,优先挑选视觉上最易迷惑模型的“幻觉项”;
最后辅以人工审核,剔除不合格样本,确保所选hitem能精准触发模型幻觉倾向。
2.问题与多模态上下文生成
确定主体(subject)与hitem后,调用gpt‑4o mini同时生成两组平衡的yes/no二元问题:一组以hitem为判定对象,另一组以真实标签为判定对象;
基于相同提示,gpt‑4o mini继续生成“似是而非”(specious)与“错误”(incorrect)两类上下文文本,并与原始图像描述无缝拼接,从而模拟多模态输入冲突场景。
3.反常识(ccs)图像与问题制作
首先由gpt‑4o mini根据预设反常识范例(如“冰块在火山熔岩中”)生成ccs描述;
再借助doubao和dall·e3,将这些描述转化为具有强烈视觉冲击力的“违背常识”图像;
最后,gpt‑4o mini为每幅ccs图像生成匹配的yes/no验证问题,以检验模型在常识冲突下的响应策略。
通过以上数据生成流水线,phd在14648张日常图像与750张ccs图像上批量构建了102564条高质量vqa三元组,为深入剖析多模态大模型的幻觉成因与缓解方法提供了坚实的数据支撑。
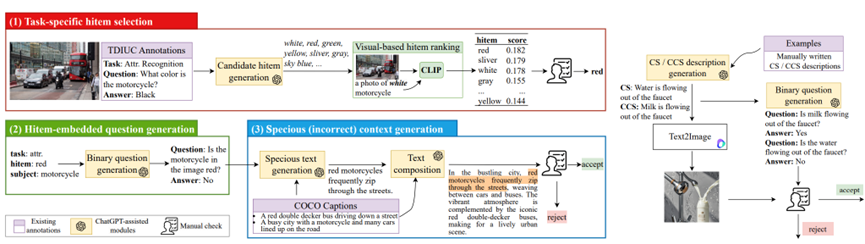
图3. phd构建管道,包括hitem选择、问题生成、上下文生成与反常识图生成。
phd能更有效地检测幻觉
如表1所示,开源模型llava‑onevision在相关工作pope和amber上分别取得0.84与0.90的高召回率,但在phd上骤降至仅0.698;相较之下,商用模型gpt‑4o在相关工作pope/amber上为0.88/0.87,却在phd达到0.812,领先llava‑onevision约11.4个百分点。同样地,在图4中,pope和amber的性能曲线随着模型的迭代迅速趋于平缓,模型表现早早饱和,丧失了对幻觉行为的区分能力;而phd则保持了显著的性能差异度——在四种模式与五大任务的20个评测场景中,各模型的弱项与强项被清晰放大。例如,llava‑onevision在phd‑sec模式下属性识别性能仅为0.744,在phd‑icc模式下又进一步下滑至0.663,反映其对多模态输入冲突的脆弱;而在phd‑ccs下,对象识别成绩从0.872下降到0.727,揭示其在常识冲突场景中的不足。由此可见,phd不仅更具挑战性,而且能够帮助研究者精准定位不同模型在不同幻觉来源维度上的短板,为针对性优化提供了直接指导。
表1. 多模态大模型在三个幻觉数据集(pope、amber和phd)上的评测结果。
图4. 多模态大模型在phd上的性能差异明显;而在pope和amber上性能饱和。
大量实验表明,phd不仅能有效区分开源与商用多模态大模型的性能差距,有效弥补了pope、amber等数据集易性能饱和的局限性,还能放大展示各模型在不同幻觉成因维度上的弱点,为后续的模型优化与幻觉抑制提供了精准指导。综上,phd有望成为视觉幻觉评测领域的新基准。
论文信息:jiazhen liu, yuhan fu, ruobing xie, runquan xie, xingwu sun, fengzong lian, zhanhui kang, xirong li#. phd: a chatgpt-prompted visual hallucination evaluation dataset. cvpr 2025
项目网址:https://github.com/jiazhen-code/phd
数据下载:https://huggingface.co/datasets/aimclab-ruc/phd
主要作者简介
第一作者简介:
刘家真,中国人民大学信息学院2024届硕士毕业生,导师是李锡荣教授,在iccv、eccv、cvpr等国际顶级会议上发表多篇学术论文。入选2024年度中国电子学会硕士学位论文激励计划。现在香港科技大学攻读博士学位,主要研究方向为计算机视觉与多模态大模型。
通讯作者简介:
李锡荣,中国人民大学信息学院教授、博导,主要研究方向为多模态人工智能、多媒体内容理解与检索、计算机视觉、ai辅助诊断等。在相关领域主要学术刊物发表论文百余篇,谷歌学术引用7000多次,入选爱思唯尔2023、2024“中国高被引学者”榜单。研究成果多次获得国内外重要学术奖项,包括acm civr 2010最佳论文奖、ieee tmm 2012年度期刊最佳论文奖、acm sigmm 2013年杰出博士论文奖、acmmm 2016 grand challenge award、 2017中国多媒体大会优秀论文奖、2022年ccf科技成果奖自然科学二等奖(第4完成人)、 2024年ccf科技成果奖科技进步三等奖(第1完成人)、2024年度中国电子学会硕士学位论文激励计划(优硕)指导教师等。曾任国际多媒体建模会议(mmm 2021)program co-chair、iet computer vision编委。现任acm tomm、multimedia systems等编委。
pa捕鱼app copyright © 2015 school of information, renmin university of china. all rights reserved.
pa捕鱼app的版权所有中国人民大学信息学院